

How to leverage spark to read in parallel from a database
 Spark Parallelization
Spark Parallelization
A usual way to read from a database, e.g. Postgres, using spark would be something like the following:
user = 'postgres'
password = 'secret'
db_driver = 'org.postgresql.Driver'
host = '127.0.0.1'
db_url = f'jdbc:postgresql://{host}:5432/dbname?user={user}&password={password}'
df = spark.read.format(
'jdbc'
).options(
url=db_url,
driver=db_driver,
dbtable='table_name',
user=user,
password=password,
fetchsize=1000, # optional, increase fetchsize to get bigger chunks - get data faster
).load()
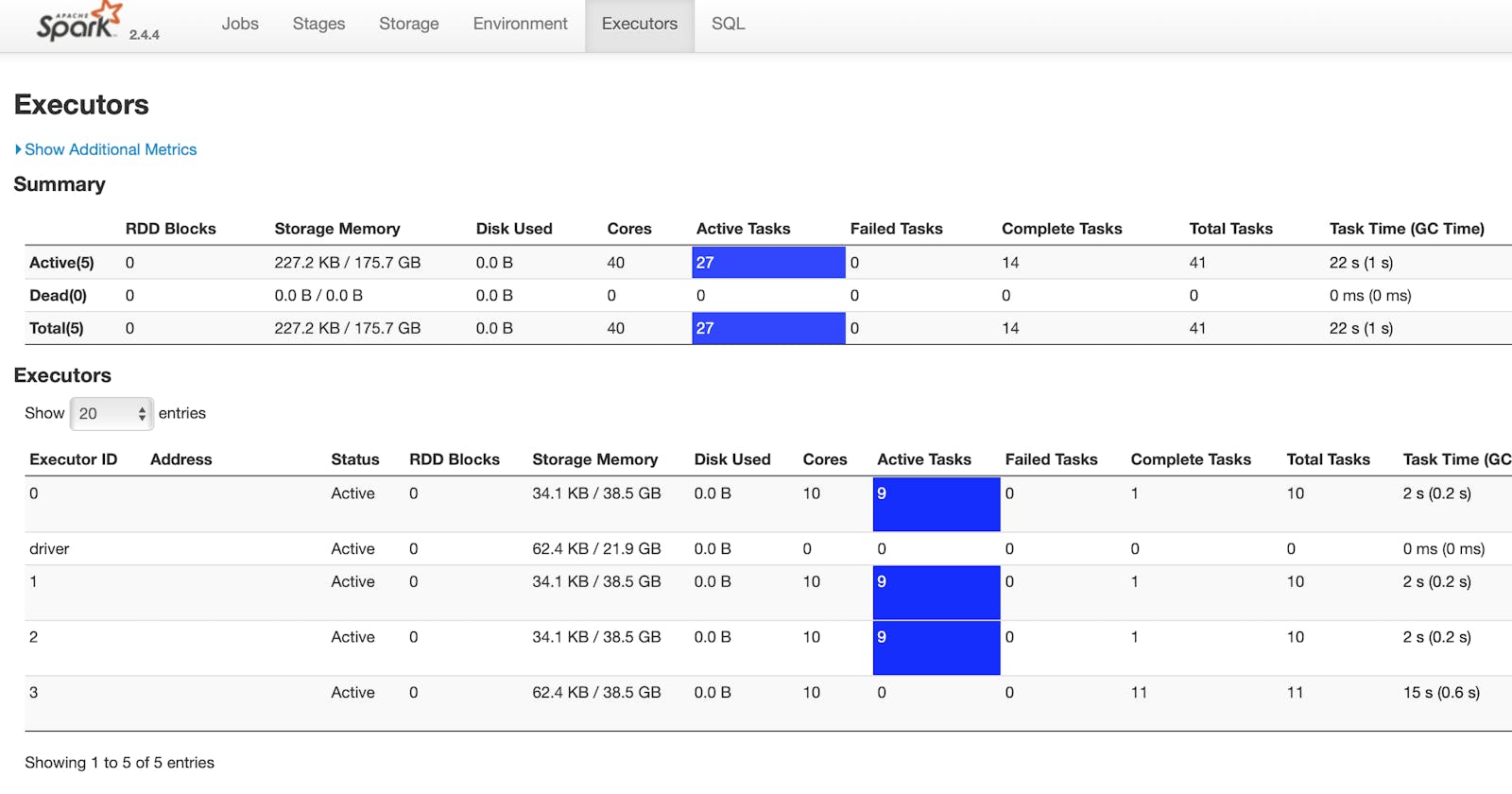
However, by running this, you will notice that the spark application has only one task active, which means, only one core is being used and this one task will try to get the data all at once. To make this more efficient, if our data permits it, we can use:
numPartitions: the number of data splitscolumn: the column to partition by, e.g.id,lowerBound: the minimum value for the column — inclusive,upperBound: the maximum value of the column —be careful, it is exclusive
To get the bounds, we can query the table first:
import os
q = '(select min(id) as min, max(id) as max from table_name where condition) as bounds'
db_url = 'localhost:5342'
partitions = os.cpu_count() * 2 # a good starting point
conn_properties = {
'user': 'username',
'password': 'password',
'driver': 'org.postgresql.Driver', # assuming we have Postgres
}
# given that we partition our data by id, get the minimum and the maximum id:
bounds = spark.read.jdbc(
url=db_url,
table=q,
properties=self.conn_properties
).collect()[0]
Notice that we use a query with the following format, (query) as something as the table parameter.
After we collect the bounds, we can then use the bounds.min and bounds.maxto efficiently query the table.
Full example:
import os
q = '(select min(id) as min, max(id) as max from table_name where condition) as bounds'
user = 'postgres'
password = 'secret'
db_driver = 'org.postgresql.Driver'
host = '127.0.0.1'
db_url = f'jdbc:postgresql://{host}:5432/dbname?user={user}&password={password}'
partitions = os.cpu_count() * 2 # a good starting point
conn_properties = {
'user': 'username',
'password': 'password',
'driver': 'org.postgresql.Driver', # assuming we have Postgres
}
# given that we partition our data by id, get the minimum and the maximum id:
bounds = spark.read.jdbc(
url=db_url,
table=q,
properties=self.conn_properties
).collect()[0]
# use the minimum and the maximum id as lowerBound and upperBound and set the numPartitions so that spark
# can parallelize the read from db
df = spark.read.jdbc(
url=db_url,
table='(select * from table_name where condition) as table_name',
numPartitions=partitions,
column='id',
lowerBound=bounds.min,
upperBound=bounds.max + 1, # upperBound is exclusive
properties=conn_properties
)
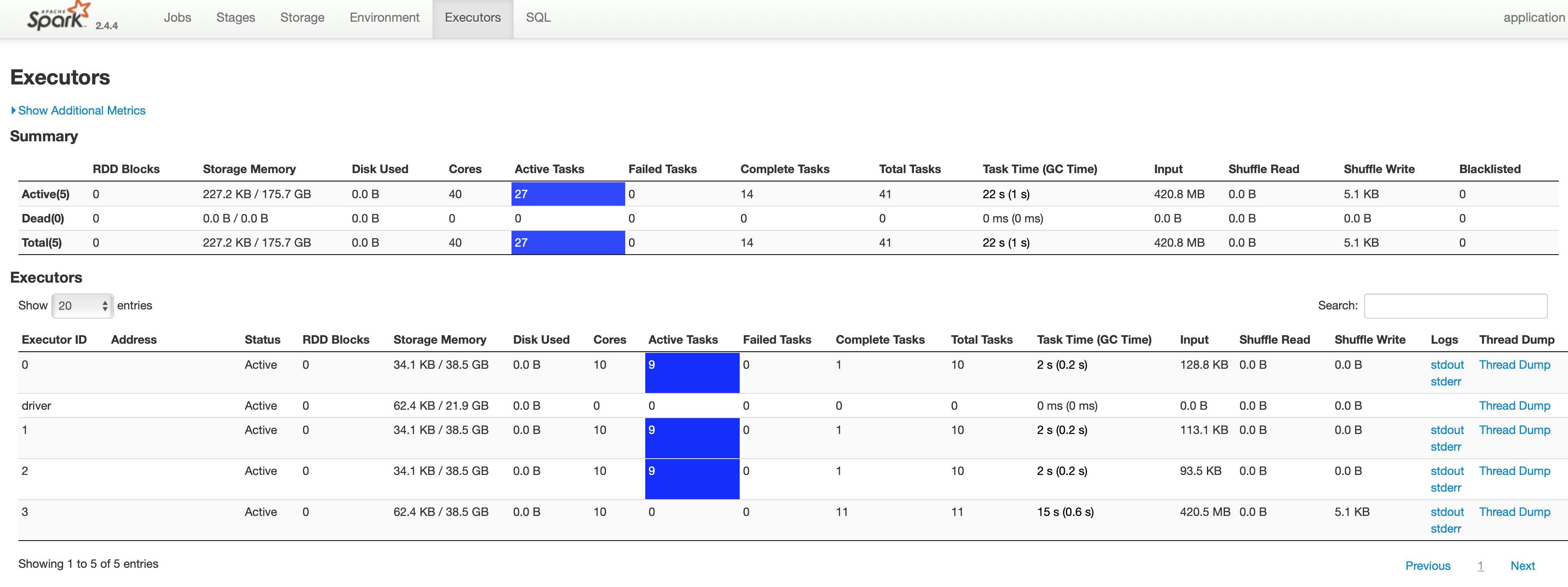
Now spark will split the data range into numPartitions tasks and each task will have ~=(bounds.max — bounds.min)/ numPartitions rows to fetch.
Note 1: the query condition must be the same in both requests, otherwise, we won’t get the correct results back.
Note 2: Of course the active tasks will be dependent on the number of cores you have, so if you have 40 cores but the number of partitions is 80, then only 40 tasks will be active at a given time. Does it make sense to have more partitions than the cores? Yes, to avoid OOM Exceptions — fetch the data in smaller parts.
Hope this helps :) Let me know if you have any questions, suggestions or corrections.