


Debugging a spark application can range from a fun to a very (and I mean very) frustrating experience.
I’ve started gathering the issues I’ve come across from time to time to compile a list of the most common problems and their solutions.
This is the first part of this list. I hope you find it useful and it saves you some time. Most of them are very simple to resolve but their stacktrace can be cryptic and not very helpful.
1. Null column returned from a udf
When you add a column to a dataframe using a udf but the result is Null: the udf return datatype is different than what was defined
For example, if you define a udf function that takes as input two numbers a and b and returns a / b , this udf function will return a float (in Python 3). If the udf is defined as:
udf_ratio_calculation = F.udf(calculate_a_b_ratio, T.BooleanType())
# or
udf_ratio_calculation = F.udf(calculate_a_b_ratio, T.DoubleType())
instead of:
udf_ratio_calculation = F.udf(calculate_a_b_ratio, T.FloatType())
then the outcome of using the udf will be something like this:
df = df.withColumn('a_b_ratio', udf_ratio_calculation('a', 'b'))
df.show()
+---+---+---------+
| a| b|a_b_ratio|
+---+---+---------+
| 1| 0| null|
| 10| 3| null|
+---+---+---------+
Full example:
from pyspark import SparkConf
from pyspark.sql import SparkSession, functions as F, types as T
conf = SparkConf()
spark_session = SparkSession.builder \
.config(conf=conf) \
.appName('test') \
.getOrCreate()
# create a dataframe
data = [{'a': 1, 'b': 0}, {'a': 10, 'b': 3}]
df = spark_session.createDataFrame(data)
df.show()
# +---+---+
# | a| b|
# +---+---+
# | 1| 0|
# | 10| 3|
# +---+---+
# define a simple function that returns a / b
def calculate_a_b_ratio(a, b):
if b > 0:
return a / b
return 0.
# and a udf for this function - notice the return datatype
udf_ratio_calculation = F.udf(calculate_a_b_ratio, T.BooleanType())
# let's use the udf to add a column to the dataframe
# even though the return type is defined wrong as T.BooleanType(), pyspark won't
# complain, but it will give you null results
df = df.withColumn('a_b_ratio', udf_ratio_calculation('a', 'b'))
df.show()
# +---+---+---------+
# | a| b|a_b_ratio|
# +---+---+---------+
# | 1| 0| null|
# | 10| 3| null|
# +---+---+---------+
# the same would be if we were defining the return type as T.DecimalType()
udf_ratio_calculation = F.udf(calculate_a_b_ratio, T.DecimalType())
df = df.withColumn('a_b_ratio_dec', udf_ratio_calculation('a', 'b'))
df.show()
# +---+---+---------+-------------+
# | a| b|a_b_ratio|a_b_ratio_dec|
# +---+---+---------+-------------+
# | 1| 0| null| null|
# | 10| 3| null| null|
# +---+---+---------+-------------+
# of course, the correct type here is T.FloatType(), and the udf works as expected
udf_ratio_calculation = F.udf(calculate_a_b_ratio, T.FloatType())
df = df.withColumn('a_b_ratio_float', udf_ratio_calculation('a', 'b'))
df.show()
# +---+---+---------+-------------+---------------+
# | a| b|a_b_ratio|a_b_ratio_dec|a_b_ratio_float|
# +---+---+---------+-------------+---------------+
# | 1| 0| null| null| 0.0|
# | 10| 3| null| null| 3.3333333|
# +---+---+---------+-------------+---------------+
2. ClassNotFoundException
This exception usually happens when you are trying to connect your application to an external system, e.g. a database. The stacktrace below is from an attempt to save a dataframe in Postgres.

This means that spark cannot find the necessary jar driver to connect to the database. We need to provide our application with the correct jars either in the spark configuration when instantiating the session
**from **pyspark **import **SparkConf
**from **pyspark.sql **import **SparkSession
conf = SparkConf()
conf.set('**spark.jars**', '**/full/path/to/postgres.jar,/full/path/to/other/jar**')
spark_session = SparkSession.builder \
.config(conf=conf) \
.appName('test') \
.getOrCreate()
or as a command line argument — depending on how we run our application.
spark-submit --jars /full/path/to/postgres.jar,/full/path/to/other/jar ...
Note 1: It is very important that the jars are accessible to all nodes and not local to the driver.
Note 2: This error might also mean a spark version mismatch between the cluster components. There other more common telltales, like AttributeError. More on this here.
Note 3: Make sure there is no space between the commas in the list of jars.
3. Low memory consumption — why doesn’t spark use up all of my resources?
Spark driver memory and spark executor memory are set by default to 1g. It is in general very useful to take a look at the many configuration parameters and their defaults, because there are many things there that can influence your spark application.
Spark Configuration
Spark provides three locations to configure the system: Spark properties control most application parameters and can be…spark.apache.org
When spark is running locally, you should adjust the spark.driver.memory to something that’s reasonable for your system, e.g. 8g and when running on a cluster, you might also want to tweak the spark.executor.memory also, even though that depends on your kind of cluster and its configuration.
from pyspark import SparkConf
from pyspark.sql import SparkSession
# depending on your set up:
# if you are running the spark app locally, set the driver memory to something your system can handle
# if you are running on a cluster, then also set the executor memory - if necessary (depends on how your cluster is configured)
conf = SparkConf()
conf.set('spark.executor.memory', '16g')
conf.set('spark.driver.memory', '8g')
spark_session = SparkSession.builder \
.config(conf=conf) \
.appName('test') \
.getOrCreate()
4. File does not exist: Spark runs ok in local mode but can’t find file when running in YARN
Again as in #2, all the necessary files/ jars should be located somewhere accessible to all of the components of your cluster, e.g. an FTP server or a common mounted drive.
spark-submit --master yarn --deploy-mode cluster http://somewhere/accessible/to/master/and/workers/test.py
5. Trying to connect to a database: java.sql.SQLException: No suitable driver
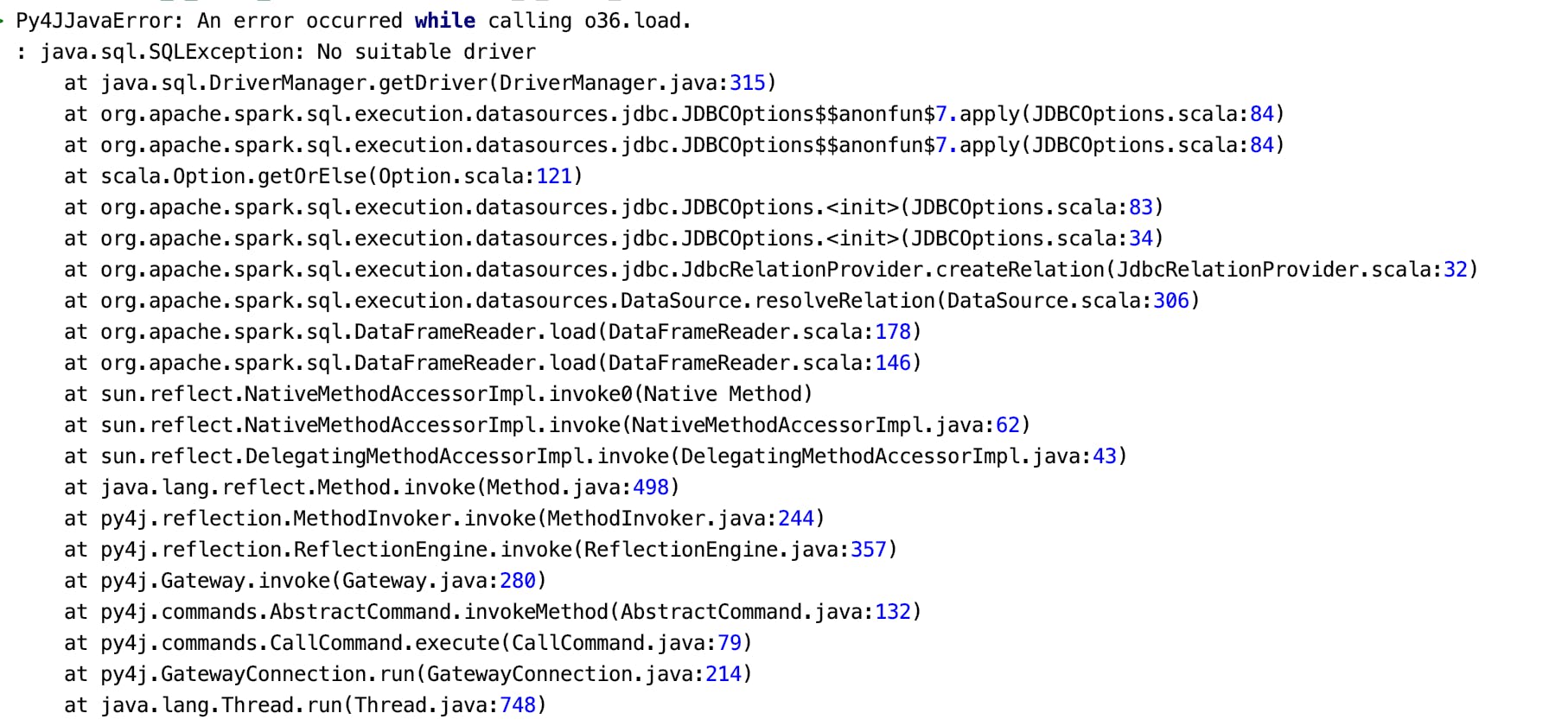
Or if the error happens while trying to save to a database, you’ll get a java.lang.NullPointerException :

This usually means that we forgot to set the **driver , e.g. `org.postgresql.Driver` **for Postgres:
df = spark.read.format(**'jdbc'**).options(
url= **'db_url'**,
driver='**org.postgresql.Driver**', # <-- here
dbtable=**'table_name'**,
user=**'user'**,
password=**'password'**
).load()
Please, also make sure you check #2 so that the driver jars are properly set.
6. ‘NoneType’ object has no attribute ‘_jvm'
You might get the following horrible stacktrace for various reasons.

Two of the most common are:
- You are using pyspark functions without having an active spark session
**from **pyspark.sql **import **SparkSession, functions **as **F
class A(object):
def __init__(self):
self.calculations = F.col('a') / F.col('b')
...
a = A() # instantiating A without an active spark session will give you this error
- Or you are using pyspark functions within a udf:
**from **pyspark **import **SparkConf
**from **pyspark.sql **import **SparkSession, functions **as **F, types **as **T
conf = SparkConf()
spark_session = SparkSession.builder \
.config(conf=conf) \
.appName('test') \
.getOrCreate()
# create a dataframe
data = [{'a': 1, 'b': 0}, {'a': 10, 'b': 3}]
df = spark_session.createDataFrame(data)
df.show()
# +---+---+
# | a| b|
# +---+---+
# | 1| 0|
# | 10| 3|
# +---+---+
# define a simple function that returns a / b
# we *cannot* use pyspark functions inside a udf
# udfs operate on a row per row basis while pyspark functions on a column basis
def calculate_a_b_max(a, b):
return F.max([a, b])
# and a udf for this function - notice the return datatype
udf_max_calculation = F.udf(calculate_a_b_ratio, T.FloatType())
df = df.withColumn('a_b_max', udf_max_calculation('a', 'b'))
df.show()
Both will give you this error.
In the last example F.max needs a column as an input and not a list, so the correct usage would be:
df = df.withColumn(**'a_max'**, F.max(**'a'**))
Which would give us the maximum of column a — not what the udf is trying to do.
The correct way to set up a udf that calculates the maximum between two columns for each row would be:
def calculate_a_b_max(a, b):
return max([a, b])
Assuming a and b are numbers.
(There are other ways to do this of course without a udf.)
I hope this was helpful. I plan to continue with the list and in time go to more complex issues, like debugging a memory leak in a pyspark application. Any thoughts, questions, corrections and suggestions are very welcome :)
If you want to know a bit about how Spark works, take a look at: Explaining technical stuff in a non-technical way — Apache Spark What is Spark and PySpark and what can I do with it?towardsdatascience.com