


What is Spark and PySpark and what can I do with it?
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/11520/0*-8mJ0H4u-y1uXEFf)
I was once asked during a presentation of the Baskerville Analytics System to explain Apache Spark to someone that is not technical at all. It kind of baffled me because I am very much used to thinking and talking in code and my mind just kept going back to technical terms, so I believe I didn’t do a great job in the very limited time I had. Let’s try this one more time, for the sake of that one person who asked me and because I believe that explaining things as simply as possible is a great skill to develop.
A side note: Sketchnoting
I’ve been reading Pencil Me In by Christina R Wodtke that talks about Sketchnoting, which the process of keeping visual notes to help in understanding and memorization. I’ve always been a visual person and used to doodle a lot throughout my childhood — which indeed helped me remember things better, and sometimes also got me into trouble. And since the whole process of me writing on Medium is so that I better understand what I think I know, and to also learn new things, I thought I’d try this again. It’s been a long long time since I last did this and I am now very much used to typing and not writing (translation: horrible sketches coming up!), so please be lenient.
The impossible homework
I guess the first thing to do is to provide an example that anyone, or almost anyone, can relate to. Thus, let’s say that you have homework that is due in a week, and what you have to do is read a really huge book, 7K pages long, and keep a count how many times the author used the term “big data” and ideally also keep the phrases that contain it (silly task but bear with me :) ).
 The “impossible” homework
The “impossible” homework
This is an impossible task, given the time constraint, even if you read day and night, you won’t be able to finish this within the week. But, you are not alone in this, so you decide to talk to your classmates and friends and figure out a solution.
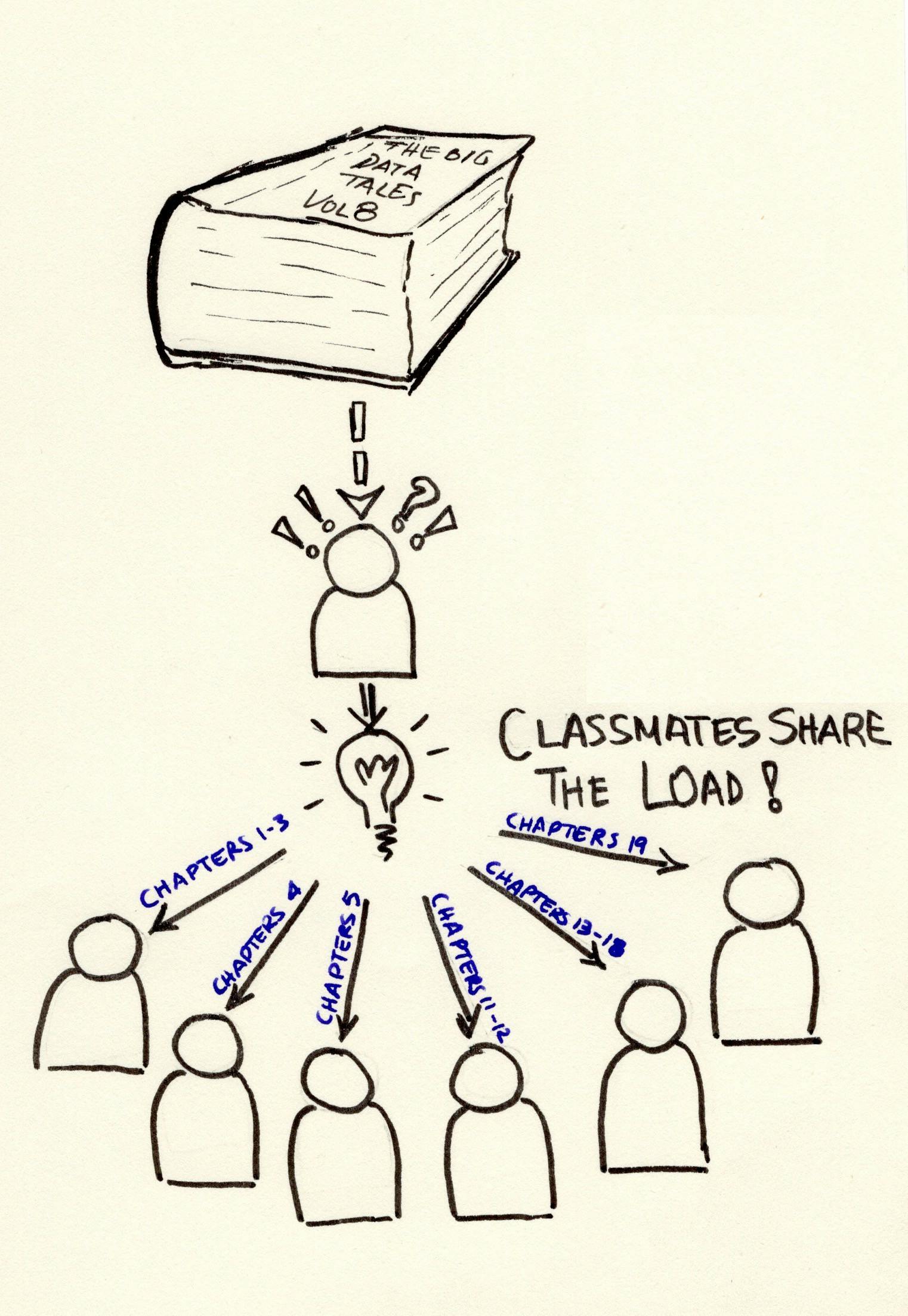
It seems logical that you split the pages and each one of you takes care of at least a couple of pages. It also makes sense that the pages each one of you takes home to read, have content that is relevant so what you’ll be reading makes sense, so you try to split by chapters.
It also looks like there is a need for a coordinator. Let’s say you take up that task since it was your idea. (You would ideally take up a chapter or two yourself, but let’s say that management and communication will take up most of your time)
 Help each other!
Help each other!
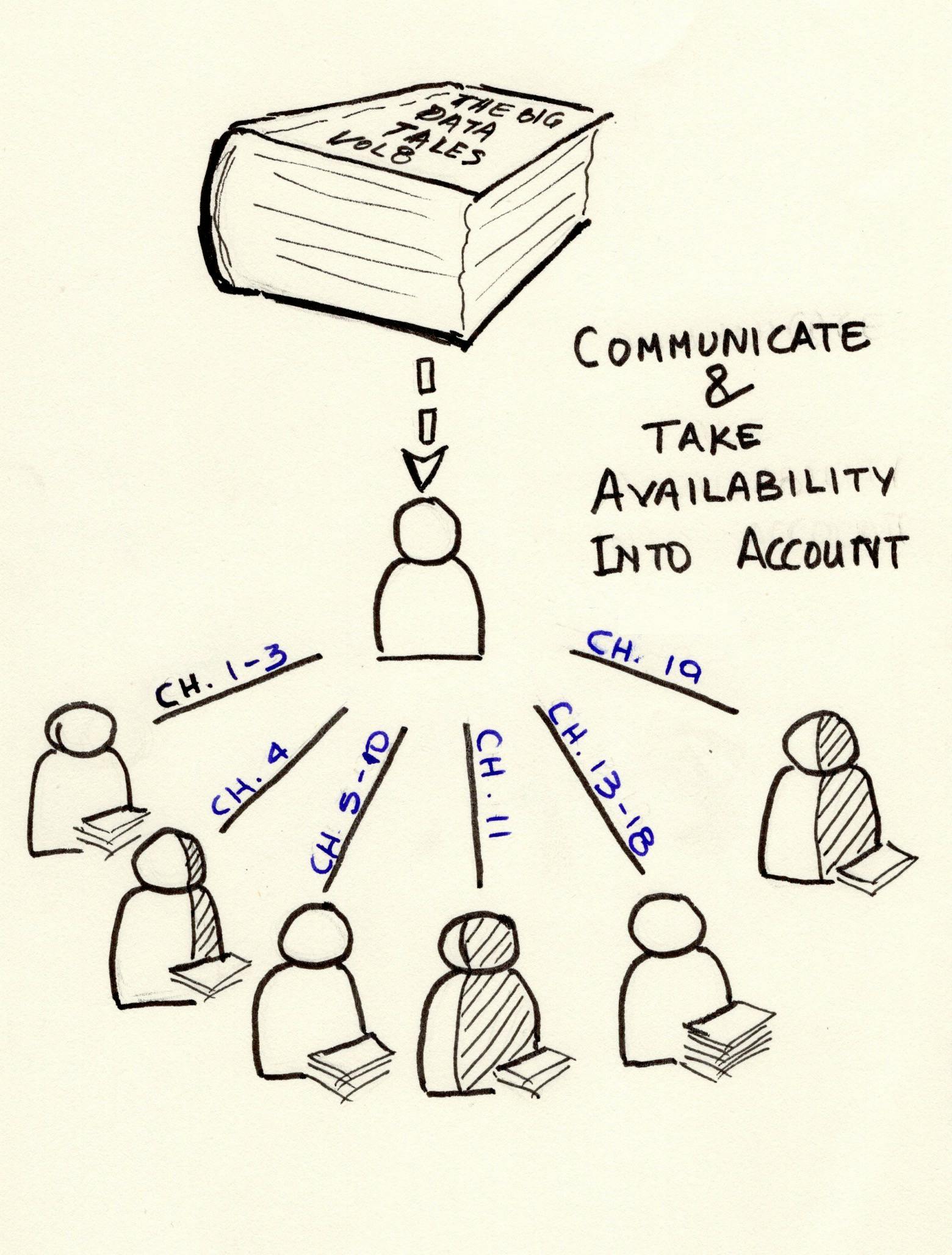
Another thing to consider is to split the pages according to who has the most time available and who is a speedy reader or a slow one so that the process is as efficient as possible, right? Also, some of you might have other homework to do within the week, so this must also be taken into account.
 Communicate with each other, know the availability and distribute work accordingly
Communicate with each other, know the availability and distribute work accordingly
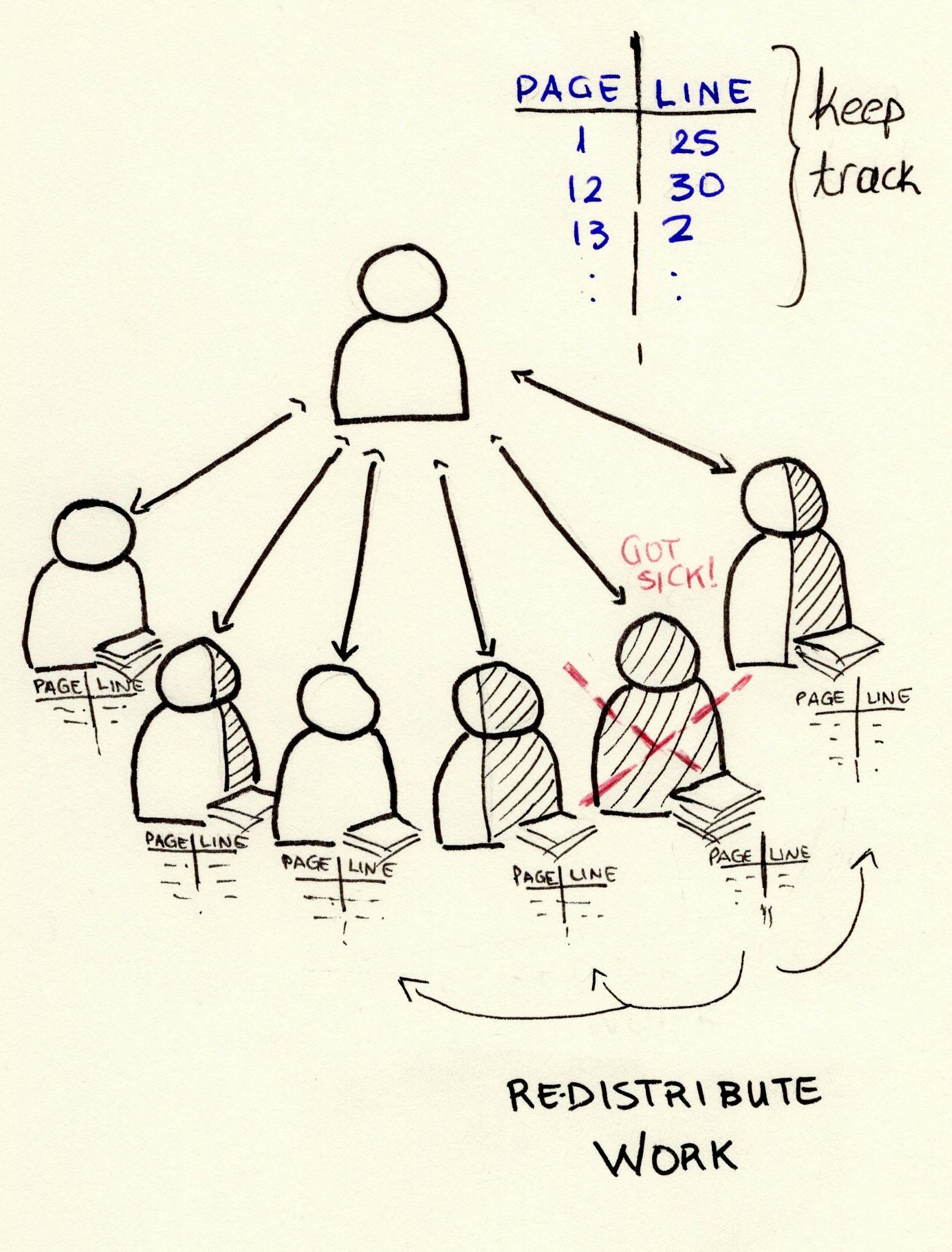
Throughout the week, it would be good to talk to your fellow students to check in and see how they’re doing. And of course, since reading the chapters will not be done at one go, use bookmarks to note your progress and keep track of where you are with the task
 Bookmark, keep track and redistribute work in case of failure
Bookmark, keep track and redistribute work in case of failure
What if you had to count more than one term? The splitting of the pages should probably be done according to the title of the chapters and the likelihood of the chapter including the terms. And what if something happens and one of you cannot complete the task? The respective pages should be redistributed to the rest of you, ideally depending on how many pages each of you has left.
In the end, you would all gather and add up your counts to have your results.
So, to sum up, to tackle this task, it makes sense to:
Split the chapters between fellow students
Have you organize things, since it was your idea and you know how things should play out
Split the chapters according to each student’s capacity — take into account reading speed and availability
Re-distribute the work if something happens and a person cannot finish up their part
Keep track of how things are going — use bookmarks, talk to your fellow students to keep track of their progress, etc.
Gather up at the end to share and combine results
How this relates to Spark and PySpark — getting a bit more technical
The homework example illustrates, as I understand it, the over-simplified basic thinking behind Apache Spark (and many similar frameworks and systems, e.g. horizontal or vertical data “sharding”), splitting the data into reasonable groups (called “partitions” in Spark’s case), given the fact that you know what kind of tasks you have to perform on the data, so that you are efficient, and distribute those partitions to ideally equal number of workers (or as many workers as your system can provide). These workers can be in the same machine or in different ones, e.g. each worker on one machine (node). There must be a coordinator of all this effort, to collect all the necessary information that is needed to perform the task and to redistribute the load in case of failure. It is also necessary to have a (network) connection between the coordinator and the workers to communicate and exchange data and information. Or even re-partition the data in case of either failure or when the computations require it (e.g. we need to calculate something on each row of data independently but then we need to group those rows by a key). There is also the concept of doing things in a “lazy” way and use caching to keep track of intermediate results and not having to calculate everything from scratch all the time.
PySpark is the python implementation of Apache Spark, which is “a unified analytics engine for large-scale data processing”.
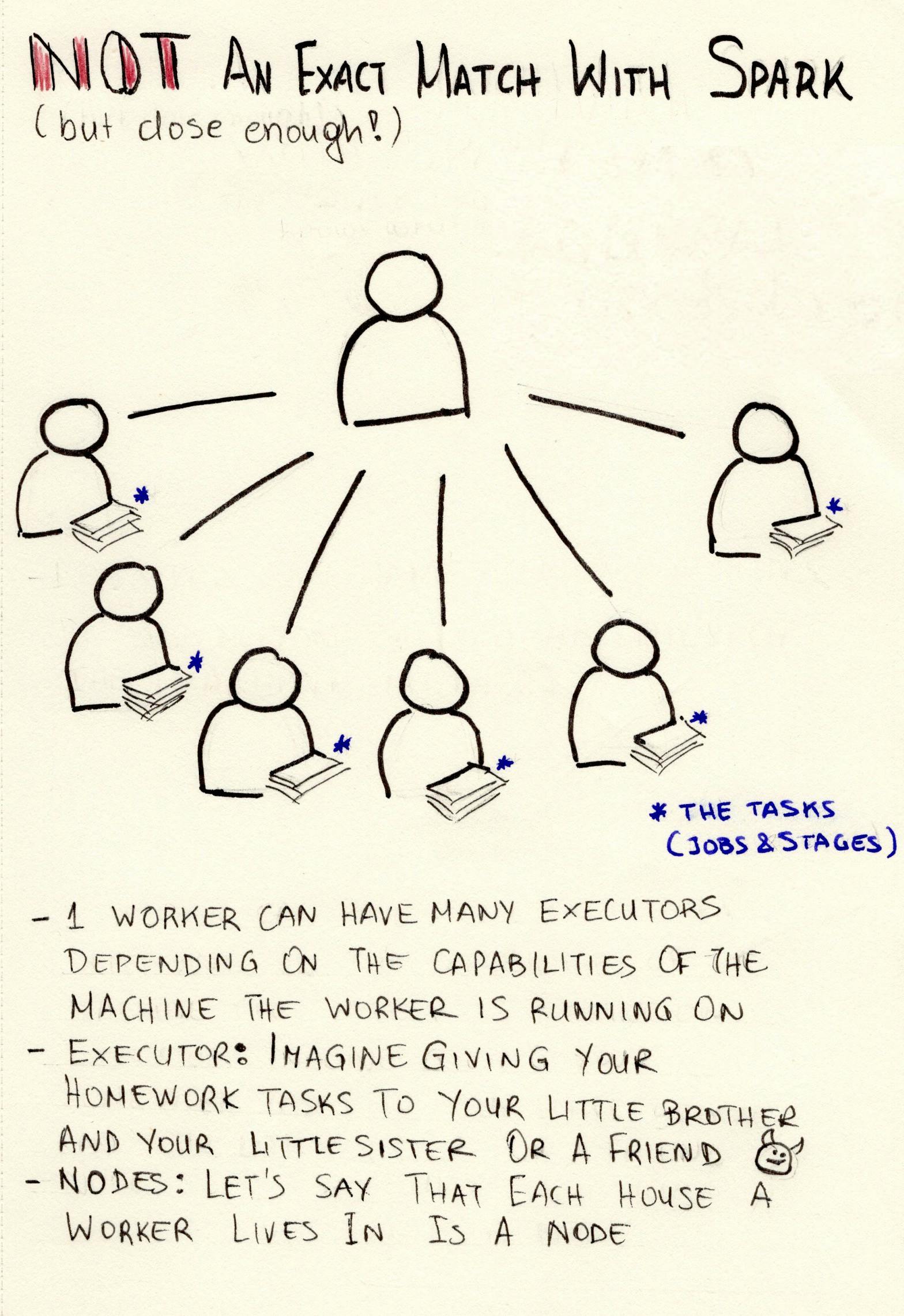
Note that this is not an exact and one-on-one comparison with the Spark components, but it is a close one conceptually. I’ve also omitted many of Spark internals and structures for the sake of simplicity. If you want to dig deeper into this, there are plenty of resources out there, starting with the official Apache Spark site.
 Comparison with Spark
Comparison with Spark
The comparison depicted in the previous image as I mentioned is not quite accurate. Let’s try again and get the teacher into the picture too. The teacher is the one who provides the homework and the instructions (the driver program), the students are split into working groups and each working group can take care of a part of the task. For the sake of brevity — and for trying to make my drawings less complicated and my life a bit easier, the image below shows the comparison of one working group to Spark. This, I feel is a bit closer to what actually goes on when a Spark application runs.
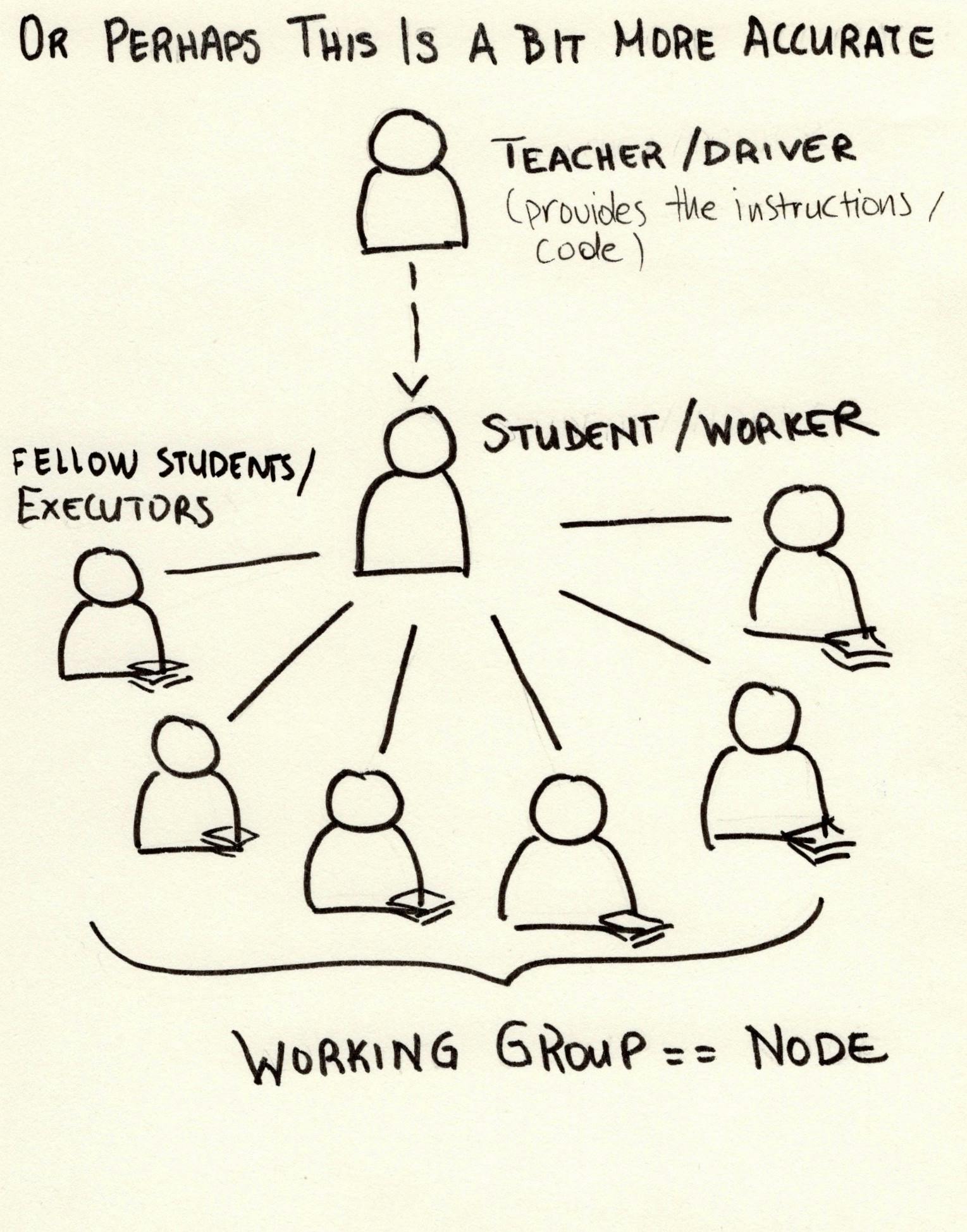 Perhaps a better comparison with Spark
Perhaps a better comparison with Spark
In simple, and a bit more technical terms, let’s say you have a huge text file (ok not big-data-huge but let’s say a 15GB file) on your computer and you really want to know how many words there are, or, as the homework above, how many times the term “big data” appears in it, along with the relevant phrases, you will be faced with the following issues:
you cannot really open this file with let’s say notepad, because even if you have 32GB of RAM, the application used to open and edit text files will be practically unusable with a 15GB file.
you can code something to count the words or a specific word or phrase in this file, either by reading line by line or using something like
wcdepending on your system, but it will be slow, very slow. And what if you need to do more complicated things?
So, immediately we see that there is no quick and easy option to do simple, let alone complex things with a big file.
One can think of several work-arounds, like splitting the huge file into many little ones and processing the little ones and adding up the results, leveraging multiprocessing techniques. And here is where Spark comes to provide an easy solution to this. Let’s see a very basic PySpark example using the python library for pyspark.
from pyspark import SparkConf
from pyspark.sql import SparkSession, functions as F
conf = SparkConf()
# optional but it would be good to set the amount of ram the driver can use to
# a reasonable (regarding the size of the file we want to read) amount, so that we don't get an OOM exception
conf.set('spark.driver.memory', '6G')
spark = SparkSession.builder \
.config(conf=conf) \
.appName('Homework-App') \
.getOrCreate()
df = spark.read.text('full/path/to/file.txt)
df = df.withColumn('has_big_data', F.when(F.col('value').contains('big data'), True).otherwise(False))
result = df.select('value').where(F.col('has_big_data')==True).count()
It looks quite simple, doesn’t it? Just a few lines of Python code. Now let’s explain a bit about what it does:
from pyspark import SparkConf
from pyspark.sql import SparkSession, functions as F
conf = SparkConf()
# optional but it would be good to set the amount of ram the driver can use to
# a reasonable (regarding the size of the file we want to read) amount, so that we don't get an OOM exception
conf.set('spark.driver.memory', '6G')
# create a spark session - nothing can be done without this:
spark = SparkSession.builder \
.config(conf=conf) \
.appName('Homework-App') \
.getOrCreate()
# spark.read.text returns a dataframe, which is easier to manipulate and also more efficient
# you can also use: spark.sparkContext.textFile('') but that will return RDD[String]
df = spark.read.text('full/path/to/file.txt)
# spark is "lazy" so, nothing has happened so far, besides the initialization of the session
# let's call .show() to see that we've actually read the file and what it looks like
df.show()
+--------------------+
| value|
+--------------------+
| 1|
| |
| Spark |
|The Definitive Guide|
|Excerpts from the...|
|big data simple w...|
| |
|By Bill Chambers ...|
| |
|http://databricks...|
|http://databricks...|
| |
| |
|Apache Spark has ...|
|several years. Th...|
|a true reflection...|
|made itself into ...|
|is proud to share...|
|Spark: The Defini...|
|courtesy of Datab...|
+--------------------+
only showing top 20 rows
# Now let's get back to the task: identify where `big data` is used.
# For this task, we add a column to the dataframe and populate it with True when `big data` is identified in a row
df = df.withColumn('has_big_data', F.when(F.col('value').contains('big data'), True).otherwise(False))
df.show()
+--------------------+------------+
| value|has_big_data|
+--------------------+------------+
| 1| false|
| | false|
| Spark | false|
|The Definitive Guide| false|
|Excerpts from the...| false|
|big data simple w...| true|
| | false|
|By Bill Chambers ...| false|
| | false|
|http://databricks...| false|
|http://databricks...| false|
| | false|
| | false|
|Apache Spark has ...| false|
|several years. Th...| false|
|a true reflection...| false|
|made itself into ...| false|
|is proud to share...| false|
|Spark: The Defini...| false|
|courtesy of Datab...| false|
+--------------------+------------+
only showing top 20 rows
# and the answer to the homework is to select the rows where the 'has_big_data' column is True
df.select('value').where(F.col('has_big_data')==True).show()
+--------------------+
| value|
+--------------------+
|big data simple w...|
|In the previous e...|
|of functions that...|
|and genomics have...|
|This part of the ...|
|When working with...|
+--------------------+
df.select('value').where(F.col('has_big_data')==True).count()
# 6 - the number of rows that contain this term
# just to see that `big data` is indeed included in these few rows :)
df.select('value').where(F.col('has_big_data')==True).show(100, False)
+----------------------------------------------------------------------------------------------------------------------+
|value |
+----------------------------------------------------------------------------------------------------------------------+
|big data simple with Apache Spark. |
|In the previous example, we created a DataFrame of a range of numbers. Not exactly groundbreaking big data. In |
|of functions that you can leverage and import to help you resolve your big data problems faster. We will use the max |
|and genomics have seen a particularly large surge in opportunity for big data applications. For example, the ADAM |
|This part of the book will cover all the core ideas behind the Structured APIs and how to apply them to your big data |
|When working with big data, the second most common task you will do after filtering things is counting things. For |
+----------------------------------------------------------------------------------------------------------------------+
There is no obvious splitting of the file into “chapters”, no coordination, no keeping track, not anything. That is because Spark will take care of all the complexity behind the scenes and we do not have to worry about telling workers and executors to read parts of the file or how to split it, or what happens if an executor drops its part suddenly and so on. So, here, we’ve done our homework in just a few lines of code.
Don’t get me wrong, Spark seems simple but there is a lot of complexity behind it and troubleshooting it is not an easy task at all, but, let’s just appreciate the good parts for now and we can talk about the difficulties later on.
Additionally, the example here is one of the simplest ones, but I believe, once you understand the mechanism and logic behind such frameworks, it is a lot easier to grasp what you can and, more importantly, cannot do with them, how to structure systems that leverage those frameworks and to get good at estimating whether doing things a certain way will be fast and efficient or not. Again, keeping this simple, I won’t go into further details about that right now.
I hope this was helpful. Any thoughts, questions, corrections and suggestions are very welcome :)